
Tesseract OCR, FOSS from the 90's
This Open Source project has been around since the 90's. And is still being improved.
https://github.com/tesseract-ocr/tesseract
It's a libary used to extract text from images and PDFs. And is the backbone of many OCR apps.
Take Kyocera Print Center's OCR option as an example.... yup that's Tesseract:
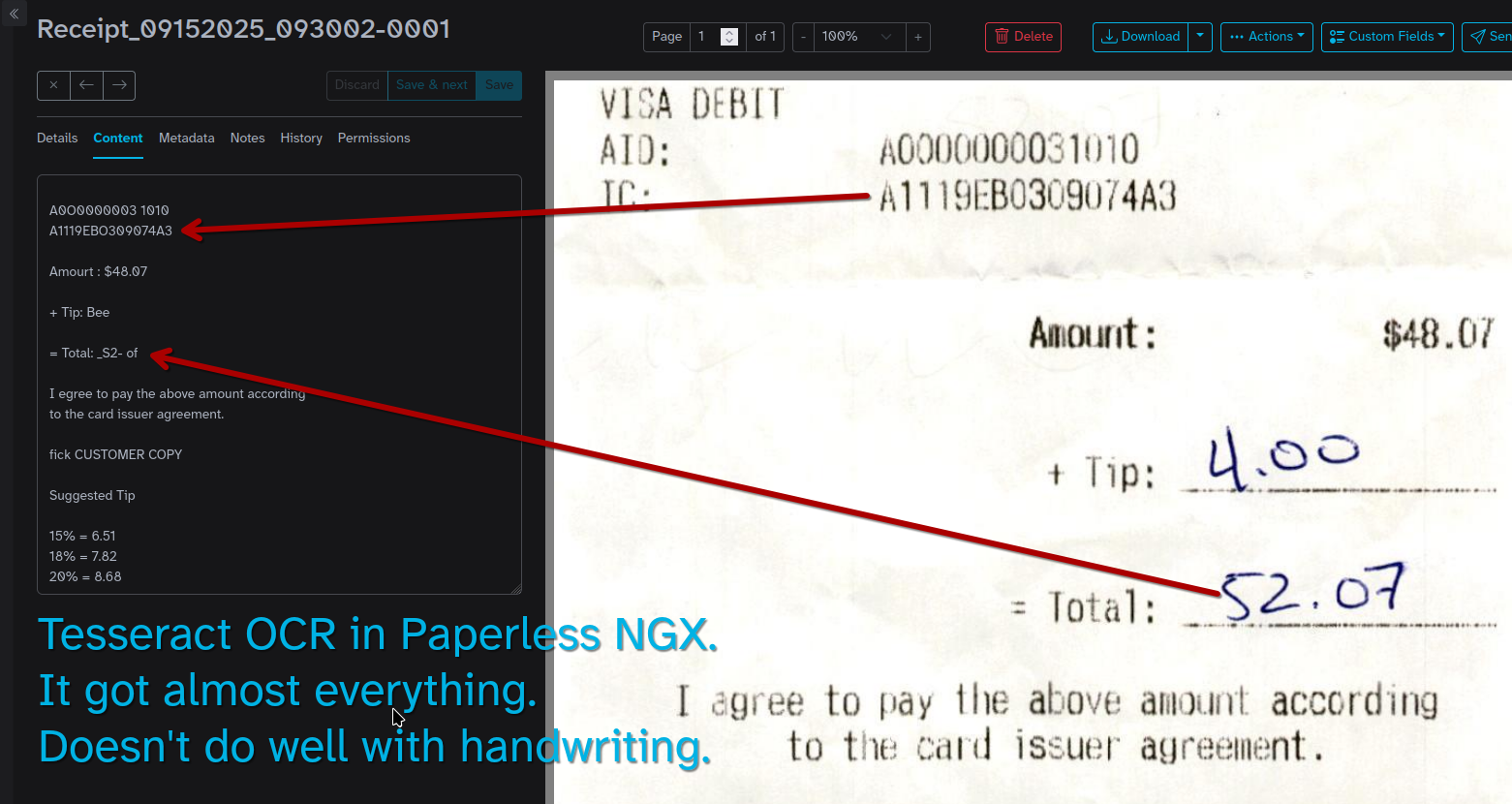
Paperless-ngx, how I use Tesseract
The Paperless project: https://docs.paperless-ngx.com/ uses Tesseract to process paper into readable and searchable text.
It does a really good job on everything except handwriting.
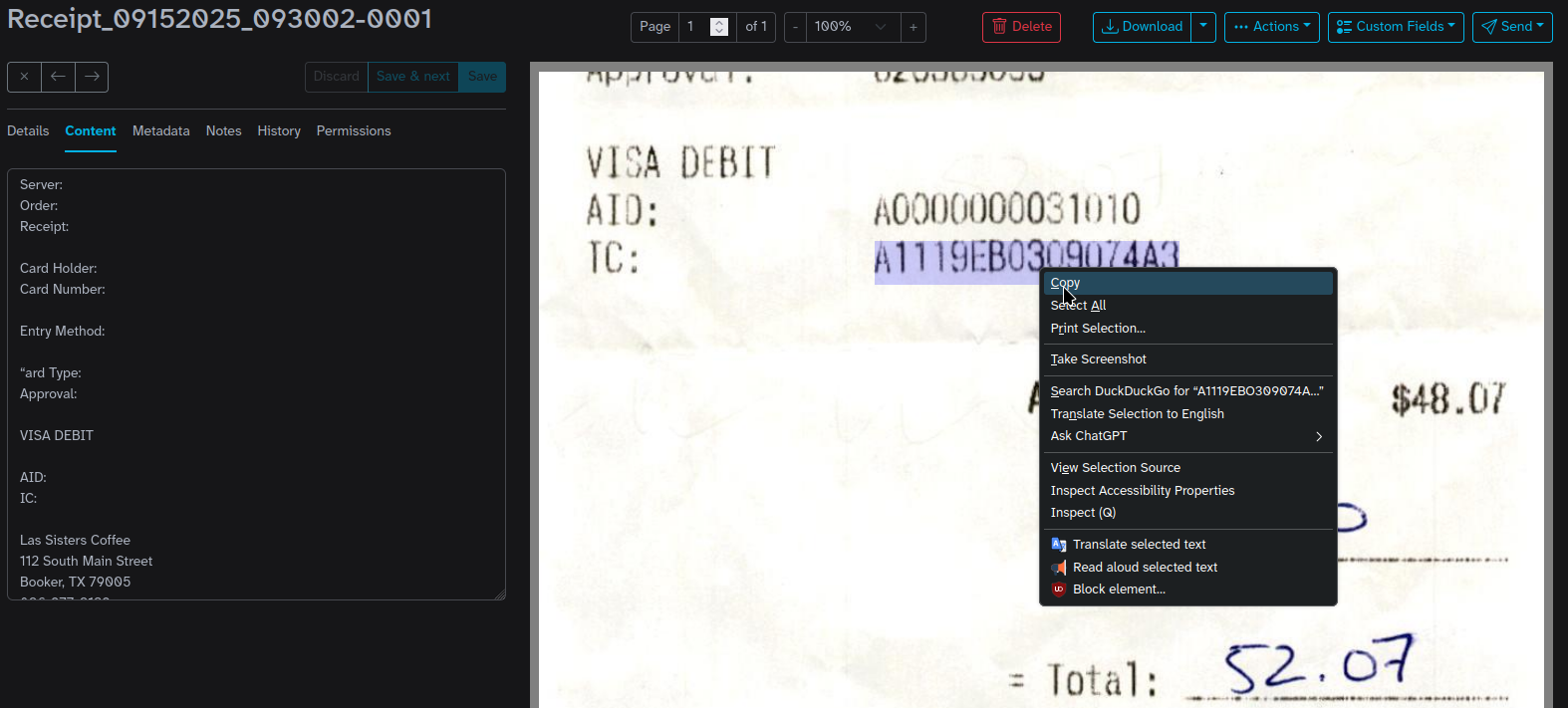
Aside from just "extraction" of text. Paperless puts the text on the PDF, so you can just search/copy/paste:
Let's compare to Google & Microsoft
SharePoint does auto OCR on images but not on PDFS. And it is not visible in a ready made way. So I've converted my plain PDF to png (an image) and uploaded it to SharePoint. And to be able to view the "MetaData" I've used PowerApps to make the "Extracted Text" visible:

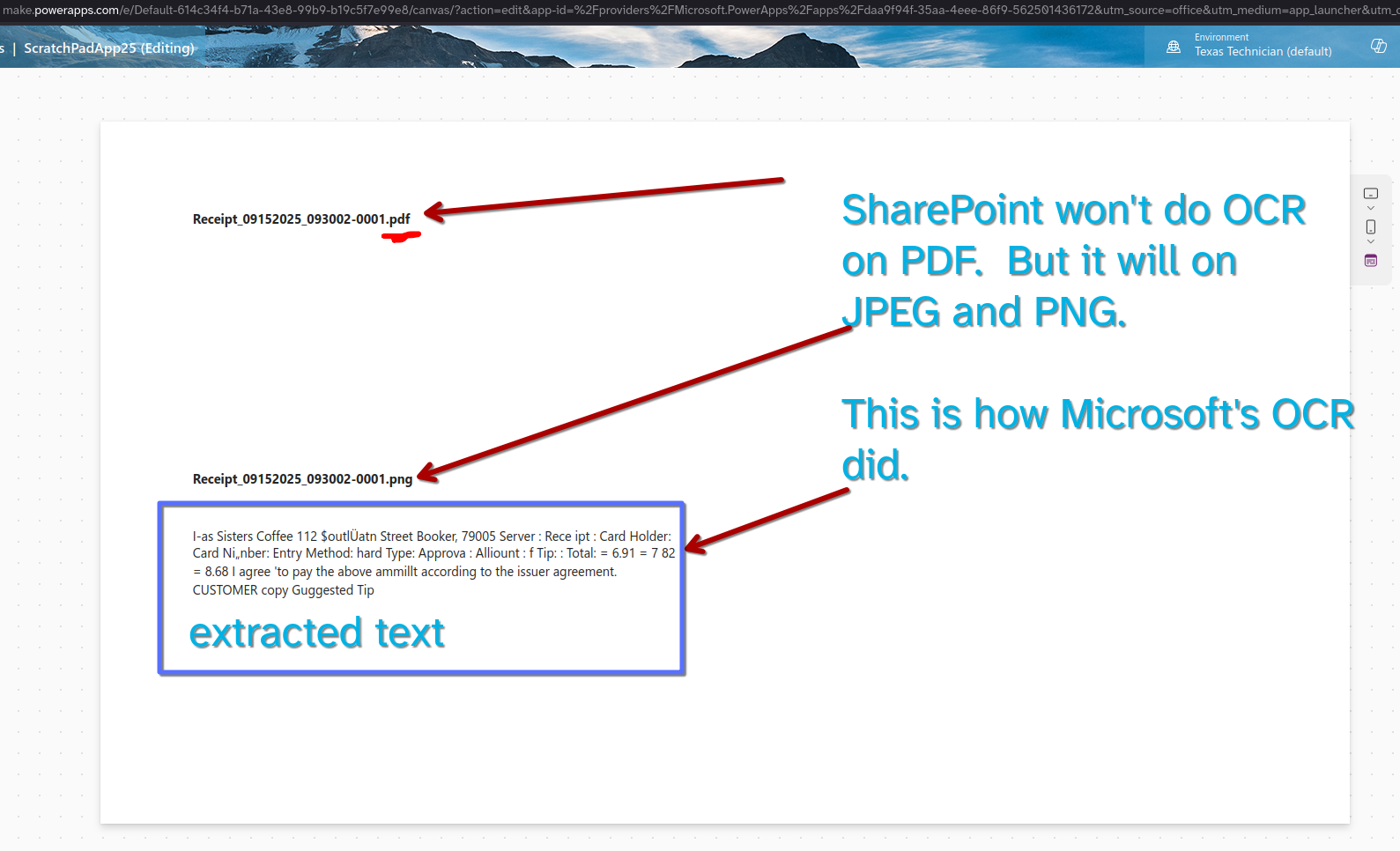
BLAH!
Google did better, but there's no way to make a searchable PDF:
AI will beat them all.... but it's not FOSS
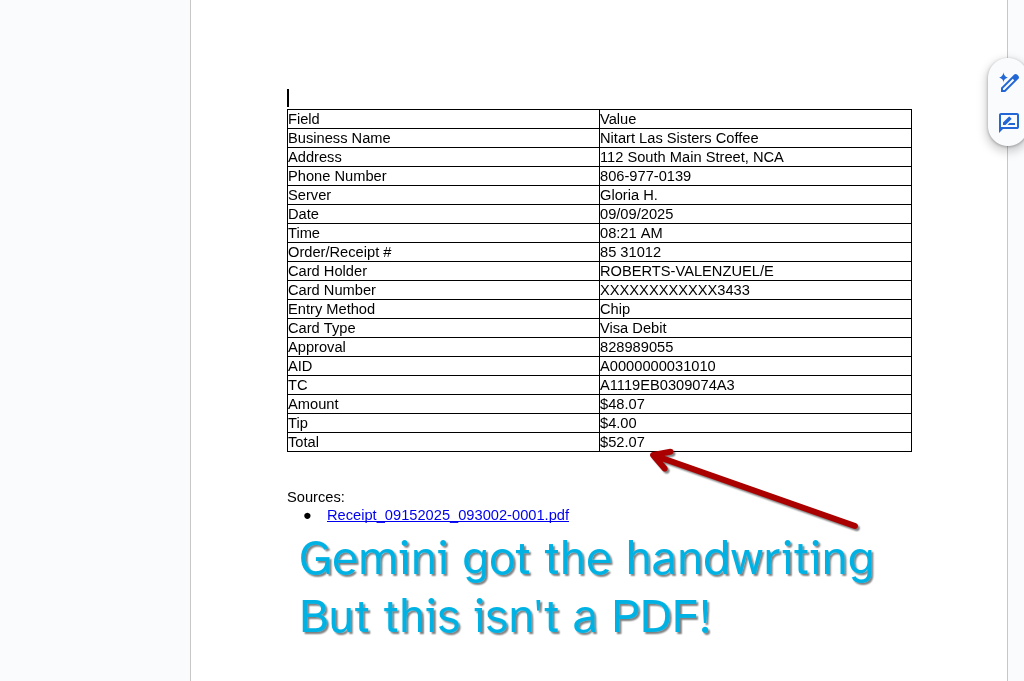
I decided to try Gemini's "extract text feature".
It got the handwriting!
Tesseract - Open Source OCR | Compared with Google and Microsoft OCR